Regulatory affairs
Global regulatory submissions, stress-free
Solution and local expertise for easier and faster global regulatory submissions

Global regulatory submissions require language technology with specific features, in line with Linguamatics' vision of meaningful innovation for healthcare and life sciences. From data safety, to scalability, speed and cost efficiency, we have the best language technology for your global regulatory affairs.
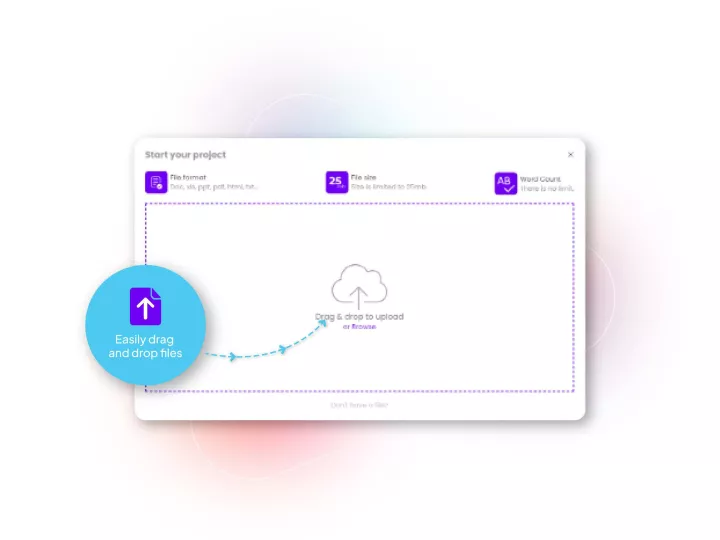
Our translation management system designed for healthcare and life sciences applications such as regulatory translations, reviews and submissions. Allows your teams to submit documents and track all the steps very simply. It is fully compliant with your enterprise data safety policies, and enables all relevant translation workflows to be accessed at the push of a button.
Affiliates can also be included for any review steps you might want them to be part of, speeding up the process in critical times.
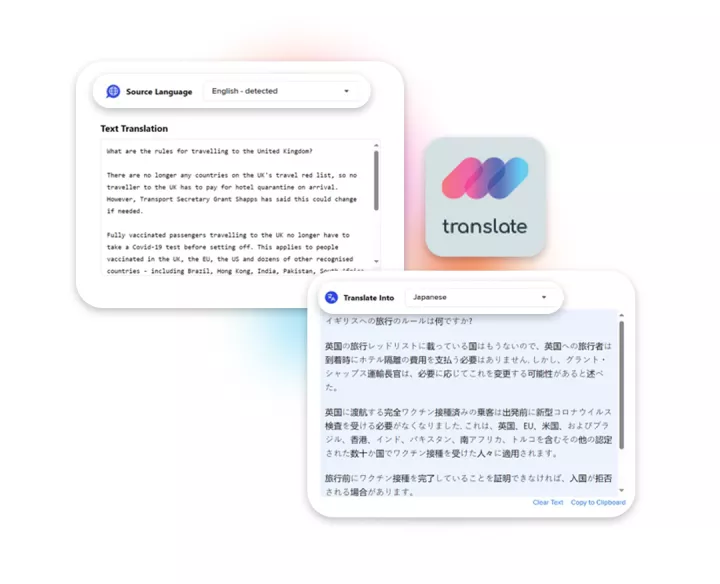
Linguamatics translate is our secure machine translation solution, leveraging the best available engines on the market as well as our proprietary engines trained with and for clinical data.
It allows for both time and cost reduction, while maintaining quality at the highest. Our expert linguists are looped in for post editing when necessary, allowing for the best of both worlds.
Linguamatics NLP is our award-winning Natural Language Processing technology which can be deployed to find, highlight, and extract key data within regulatory documents, check for MedDRA coding, mark up inconsistencies across documents, and more.
Linguamatics technology allows your organization to benefit from massive efficiencies, while providing all employees with reliable and compliant language solutions at their fingertips.

Accurate regulatory intelligence is essential for better decision-making for regulatory teams. Our natural language processing can be used to find, extract and compare drug label information with simple and rapid capture of relevant labeling documents from diverse sources such as:

Our NLP solution can save organizations time and money by finding, extracting, standardizing and structuring the required data elements from IDMP-relevant unstructured text documents, including:
